Unfinish
本文最后更新于:2023年8月25日 下午
[网鼎杯2018]Unfinish
登录进去,发现login.php,然后目录扫描发现 register.php
注册后登陆进去,发现显示出来了我们的用户名username,这个是二次注入
我们猜测插入数据库的语句为:
1 | |
这里又学到一个新的东西:
1 | |
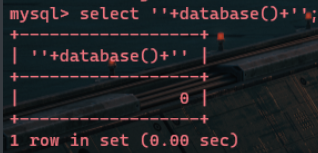
这样查询出来的结果为0,但是如果我们将 database() 进行hex编码:
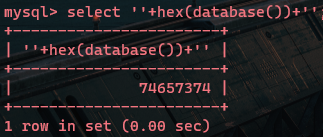
发现可以查询出数据库名被hex编码后的结果
我们想用这样的思路查询flag:
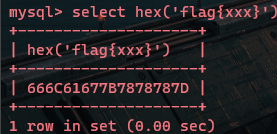
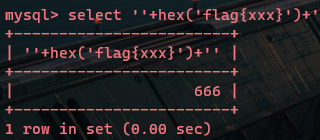
发现hex值被截断了,因为其中包含了英文字母,我们再次hex编码一次:
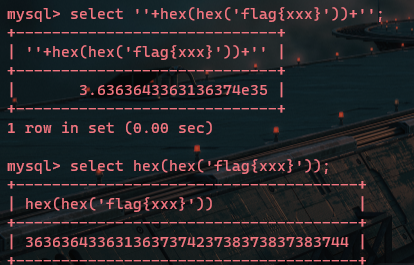
我们发现flag两次hex编码后的值成了科学计数法,这样就可以逐字符盲注了。
还有另一种方法,使用ascii()将字符转为ascii码,这样就可以慢慢盲注了
但是我们不知道库名、表名、列名,这里别人是选择盲猜,猜flag在flag表中
我们先爆破一下过滤了哪些字符,发现 information , 被过滤了
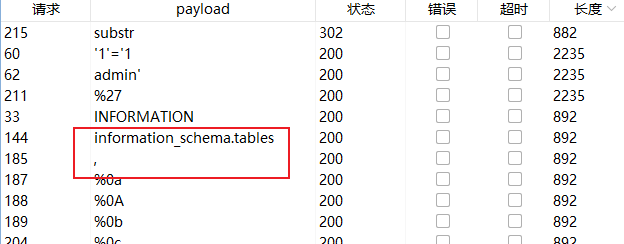
由于是逐字符获取,所以我们需要使用 substr() 但是这个函数需要使用逗号。
但是有不需要逗号的写法: substr(xxx from 1 for 1)
我们直接写脚本:
1 | |
这里复习了一下 爬虫的 bs4模块:
BeautifulSoup4 (bs4) 是一个 Python 的 HTML/XML 解析库,用于从 HTML 或 XML 中提取数据。它提供了多种方法来定位和提取 HTML 或 XML 标记(tag),包括以下常用方法:
BeautifulSoup():将 HTML 或 XML 文档转换为一个 BeautifulSoup 对象,便于使用各种方法提取数据。
find()和find_all():在 HTML 或 XML 文档中查找指定的标签或一组标签,并返回一个或多个 Tag 对象。
get():获取指定标签的指定属性的值。
text属性:获取指定标签的文本内容。
prettify():将 BeautifulSoup 对象的 HTML 或 XML 格式化输出,以便于阅读和调试。以下是一个使用 bs4 的示例程序,演示如何从 HTML 文档中提取数据:
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21from bs4 import BeautifulSoup
import requests
# 发送 HTTP GET 请求,并获取响应内容
response = requests.get('https://www.example.com/')
html_doc = response.content
# 将 HTML 文档转换为 BeautifulSoup 对象
soup = BeautifulSoup(html_doc, 'html.parser')
# 查找第一个 h1 标签,并输出其文本内容
h1_tag = soup.find('h1')
print(h1_tag.text)
# 查找所有 a 标签,并输出其 href 属性的值和文本内容
a_tags = soup.find_all('a')
for a in a_tags:
print(a.get('href'), a.text)
# 格式化输出 BeautifulSoup 对象
print(soup.prettify())这个程序首先发送一个 HTTP GET 请求,获取 https://www.example.com/ 的响应内容。然后将响应内容转换为 BeautifulSoup 对象,并使用各种方法从 HTML 文档中提取数据,包括查找标签、获取属性值和文本内容,以及格式化输出 BeautifulSoup 对象。
这里我们使用了如下代码:
1 | |
先创建一个 BeautifulSoup对象,使用了html解析
然后使用对象的find()方法 ,用于查找 网页中第一个 span标签,并且类名为 user-name 的标签
然后使用了 text属性获取其中的文本,转为int后再转为字符输出
知识点
经过测试mysql中 +的作用是用来进行数学运算
两个数字相加,返回两数之和
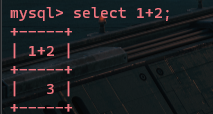
一个字符数字与一个数字相加,返回两数之和:
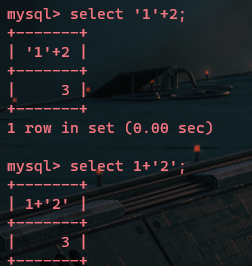
一个字符与一个数字相加,返回数字本身:(把字符转化为了0,所以相加就是该数字)
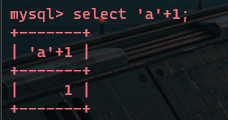
两个字符相加,返回数字0:
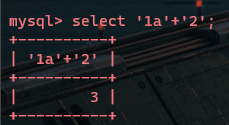
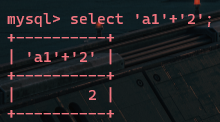
一个数字与一个以数字开头的字符串相加,返回该数字与该字符串第一个字符前的数字值之和
(原因可能是弱类型转化,把以数字开头的字符串后面的字符给去掉了)
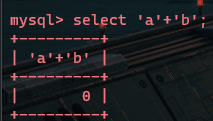
以字符开头的字符串与数值型相加,该字符串值为0
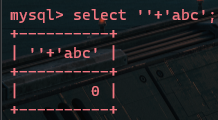
空字符串与字符串相加,由于弱类型转化,所以为0
所以本题需要将flag转化为数值,才能盲注出来