xss漏洞
本文最后更新于:2023年6月5日 下午
一、初识XSS
1、什么是XSS
XSS全称跨站脚本(Cross Site Scripting),为避免与层叠样式表(Cascading Style Sheets, CSS)的缩写混淆,故缩写为XSS。这是一种将任意 Javascript 代码插入到其他Web用户页面里执行以达到攻击目的的漏洞。攻击者利用浏览器的动态展示数据功能,在HTML页面里嵌入恶意代码。当用户浏览改页时,这些潜入在HTML中的恶意代码会被执行,用户浏览器被攻击者控制,从而达到攻击者的特殊目的,如 cookie窃取等。
2、XSS产生原因、漏洞原理
形成XSS漏洞的主要原因是程序对输入和输出的控制不够严格,导致“精心构造”的脚本输入后,在输到前端时被浏览器当作有效代码解析执行从而产生危害。
3、XSS会造成那些危害?
攻击者通过Web应用程序发送恶意代码,一般以浏览器脚本的形式发送给不同的终端用户。当一个Web程序的用户输入点没有进行校验和编码,将很容易的导致XSS。
1 | |
4、XSS的防御
形成XSS漏洞的主要原因是程序对输入和输出的控制不够严格,导致“精心构造”的脚本输入后,在输到前端时被浏览器当作有效代码解析执行从而产生危害。
因此在XSS漏洞的防范上,一般会采用“对输入进行过滤”和“输出进行转义”的方式进行处理: 输入过滤:对输入进行过滤,不允许可能导致XSS攻击的字符输入; 输出转义:根据输出点的位置对输出到前端的内容进行适当转义;
5、XSS常见出现的地方
1、数据交互的地方
get、post、cookies、headers
反馈与浏览
富文本编辑器
各类标签插入和自定义
2、数据输出的地方
用户资料
关键词、标签、说明
文件上传
6、XSS的分类
反射性XSS
又称非持久型XSS,这种攻击方式往往具有一次性,只在用户单击时触发。跨站代码一般存在链接中,当受害者请求这样的链接时,跨站代码经过服务端反射回来,这类跨站的代码通常不存储服务端
1 | |
存储型XSS
存储型XSS( Stored xss Attacks),也是持久型XSS,比反射型XSS更具有威胁性。。攻击脚本将被永久的存放在目标服务器的数据库或文件中。这是利用起来最方便的跨站类型,跨站代码存储于服务端(比如数据库中)
1 | |
DOM型XSS
DoM是文档对象模型( Document Object Model)的缩写。它是HTML文档的对象表示,同时也是外部内容(例如 JavaScript)与HTML元素之间的接口。解析树的根节点是“ Document”对象。DOM( Document object model),使用DOM能够使程序和脚本能够动态访问和更新文档的内容、结构和样式。
它是基于DoM文档对象的一种漏洞,并且DOM型XSS是基于JS上的,并不需要与服务器进行交互。
其通过修改页面DOM节点数据信息而形成的ⅩSS跨站脚本攻击。不同于反射型XSS和存储型XSS,基于DOM的XSS跨站脚本攻击往往需要针对具体的 Javascript DOM代码进行分析,并根据实际情况进行XSS跨站脚本攻击的利用。
一种基于DOM的跨站,这是客户端脚本本身解析不正确导致的安全问题
1 | |
反射型XSS与DOM型区别:
1、反射型XSS攻击中,服务器在返回HTML文档的时候,就已经包含了恶意的脚本;
2、DOM型ⅩSS攻击中,服务器在返回HTML文档的时候,是不包含恶意脚本的;恶意脚本是在其执行了非恶意脚本后,被注入到文档里的
通过JS脚本对对文档对象进行编辑,从而修改页面的元素。也就是说,客户端的脚本程序可以DOM动态修改页面的内容,从客户端获取DOM中的数据并在本地执行。由于DOM是在客户端修改节点的,所以基于DOM型的XSS漏洞不需要与服务器端交互,它只发生在客户端处理数据的阶段。
7、常见标签
<img>标签
利用方式1
1 | |
img STYLE=”background-image:url(javascript:alert(‘XSS’))”
XSS利用方式2
1 | |
XSS利用方式3
1 | |
<a>标签
标准格式
1 | |
XSS利用方式1
2
3<a href="javascript:alert('xss')">aa</a>
<a href=javascript:eval(alert('xss'))>aa</a>
<a href="javascript:aaa" onmouseover="alert(/xss/)">aa</a>
XSS利用方式2
利用方式3
1 | |
利用方式4
1 | |
input标签
标准格式
1 | |
利用方式1
1 | |
利用方式2
1 | |
利用方式4
1 | |
<form>标签
XSS利用方式1
2<form action=javascript:alert('xss') method="get">
<form action=javascript:alert('xss')>
XSS利用方式2
2
3<form method=postaction=aa.asp?onmouseover=prompt('xss')>
<form method=postaction=aa.asp?onmouseover=alert('xss')>
<form action=onmouseover=alert('xss)>
XSS利用方式3
原code
<form method=postaction="data:text/html;base64,<script>alert('xss')</script>">base64编码
<form method=postaction="data:text/html;base64,PHNjcmlwdD5hbGVydCgneHNzJyk8L3NjcmlwdD4=">
<iframe>标签
XSS利用方式1
1 | |
XSS利用方式2
1 | |
原code
1 | |
base64编码 使用data伪协议,当某些关键字被过滤时使用
1 | |
XSS利用方式3
1 | |
XSS利用方式3
1 | |
svg<>标签
1 | |
二、session与cookie
session
由于HTTP协议是无状态的协议,所以服务端需要记录用户的状态时,就需要用某种机制来识具体的用户,这个机制就是 Session
典型的场景比如购物车,当你点击下单按钮时,由于HTTP协议无状态,所以并不知道是哪个用户操作的,所以服务端要为特定的用户创建了特定的 Session,用用于标识这个用户,并且跟踪用户,这样才知道购物车里面有几本书。
这个 Session是保存在服务端的,有一个唯一标识。在服务端保存 Session的方法很多,内存、数据库、文件都有。集群的时候也要考虑 Session的转移,在大型的网站一般会有专门的 Session服务器集群,用来保存用户会话,这个时候 Session信息都是放在内存的,使用一些缓存服务比如 Memcached之类的来放 Session。
cookie
思考一下服务端如何识别特定的客户?这个时候 Cookie就登场了。
每次HTTP请求的时候,客户端都会发送相应的Cookie信息到服务端。实际上大多数的应用都是用 Cookie来实现 Session跟踪的,第一次创建 Session的时候,服务端会在HTTP协议中告诉客户端,需要在Cookie里面记录个SessionID,以后每次请求把这个会话ID发送到服务器,我就知道你是谁了。
设想你某次登陆过一个网站,只需要登录一次就可以在一定时间内浏览这个网站的所有内容,这是如何做到的?也是 Cookie
Cookie是指某些网站为了辨别用户身份而储存在客户端上的数据(通常经过加密)。也就是说,只要有了某个用户的 cookie,就能以他的身份登录
获取cookie:
浏览器(客户端):document.cookie
服务器端(php):$_COOKIE
举例

知道了 cookie的格式, cookie的属性选项,接下来我们就可以设置 cookie了。首先得明确一点:cookie既可以由服务端来设置,也可以由客户端来设置。
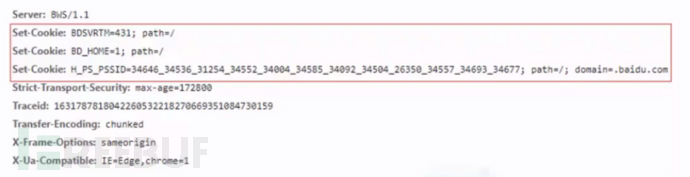
1、一个Set-Cookie字段只能设置一个 cookie,当你要想设置多个 cookie,需要添加同样多的Set- Cookie字段。 2、服务端可以设置 cookie的所有选项:expires、 domain、path、 secure、 HttpOnly

客户端可以设置 cookie的下列选项:expires、 domain、path、 secure(有条件:只有在https协议的网页中,客户端设置 secure类型的 cookie才能成功),但无法设置 HttpOnly选项。
三、浏览器解析方式
语言的解析般分为词法分析( lexical analysis)和语法分析( Syntax analysis)两个阶段, Webkit中的HTML解析也不例外,我们这里主要关注词法分析。
词法分析的任务是对输入字节流进行逐字扫描,根据构词规则识别单词和符号,分在WebKⅰt中,有两个类,同词法分析密切相关,它是 HTMLToken和HTMLTokenizer类,可以简单将 HTMLToken类理解为标记, HTMLTokenizer类理解为词法解析器。HTML词法解析的任务,就是将输入的字节流解析成一个个的标记( HTMLToken),然后由语法解析器进行下一步的分析
在XML/HTML 的文档解析中, token这个词经常用到,我将其理解为一个有完整语义的单元(也就是分出来的“词”),一个元素通常对应于3个 token,一个是元素的起始标签,一个是元素的结束标签,一个是元素的内容,这点同DOM树是不一样的,在DOM树上,起始标签和结束标签对应于一个元素节点,而元素内容对应另一个节点。
除了起始标签( StartTag)、结束标签(仼 drAg)和元素内容( Character),HTM标签还有 DOCTYPE(文档类型) Comment(注释), Uninitialized(默认类型)和EndofFile(文档结束)等类型,参见 HTMLToken h中的Type枚举。
在HTML中,某些字符是预留的。例如在HTML中不能使用<或>,这是因为浏览器可能误认为它们是标签的开始或结束。如果希望正确地显示预留字符,就需要在HTML中使用对应的字符实体。一个HTML字符实体描述如下
字符显示 描述 实体名称 实体编号
< 小于号 <<
需要注意的是,某些字符没有实体名称,但可以有实体编号
HTML的词法分析:http://www.w3.org/TR/html5/tokenization.html
HTML的规范是相当宽松的,所以词法解析要考虑到的问题很多,HTML5 specification 在这方面为实现者做了绝大部分工作。 不考虑类似<html>和<body>之间的回车换行
……
四、XSS总结与拓展
(1)输入在标签间的情况:测试<>是否被过滤或转义,若无则直接<mgsc=1 onerror=alert(1)>
(2)输入在 script标签内:我们需要在保证内部JS语法正确的前提下,去插入我们的 payload。如果我们的输岀在字符串内部,测试字符串能否被闭合。如果我们无法闭合包裹字符串的引号,这个点就很难利用了
可能的解决方案:可以控制两处输入且\可用、存在宽字节
(3)输入在HTML属性內:首先査看属性是否有双引号包裏、没有则直接添加新的事件属性;
有双引号包裹则测试双引号是否可用,可用则闭合属性之后添加新的事件属性;
TIP:HTML的属性,如果被进行HTML实体编码(形如';'),那么HTML会对其进行自动解码,从而我们可以在属性里以HTML实体编码的方式引入任意字符,从而方便我们在事件属性里以JS的方式构造 payload。
(4)输岀在JS中,空格被过滤:使用/**/代替空格。 (5)输出在JS注释中:设法插入换行符%0A,使其逃逸出来。 (6)输入在JS字符串内:可以利用JS的十六进制、八进制、 unicode编码。 (7)输入在src/ href /action等属性内:可以利用 javascript:alert(1),以及data:text/html;base64;加上base64编码后的HTML
(8) Chrome下 iframe自身的弹框姿势
1 | |
(9)坑点之自带 HtmlEncode(转义)功能的标签
1 | |
当我们的 XSS payload位于这些标签中间时,并不会解析,除非我们把它们闭合掉。