pickle反序列化
本文最后更新于:2023年9月6日 晚上
[TOC]
pickle反序列化
什么是pickle?
pickle是Python中一个能够序列化和反序列化对象的模块。和其他语言类似,Python也提供了序列化和反序列化这一功能,其中一个实现模块就是pickle。在Python中,“Pickling” 是将 Python 对象及其所拥有的层次结构转化为一个二进制字节流的过程,也就是我们常说的序列化,而 “unpickling” 是相反的操作,会将字节流转化回一个对象层次结构。
pickle实际上可以看作一种独立的语言,通过对opcode的编写可以进行Python代码执行、覆盖变量等操作。直接编写的opcode灵活性比使用pickle序列化生成的代码更高,并且有的代码不能通过pickle序列化得到(pickle解析能力大于pickle生成能力)。

pickle库及函数
| 函数 | 说明 |
|---|---|
| dumps | 对象反序列化为bytes对象 |
| dump | 对象反序列化到文件对象,存入文件 |
| loads | 从bytes对象反序列化 |
| load | 对象反序列化,从文件中读取数据 |
先通过几个例子来看下这几个函数的作用:
dump/load(文件)
1 | |
dumps/loads(二进制字节流)
1 | |
示例:
1 | |
这里我创建了一个Person类,其中有两个属性age和name。我首先使用了pickle.dumps()函数将一个Person对象序列化成二进制字节流的形式。然后使用pickle.loads()将一串二进制字节流反序列化为一个Person对象。
可序列化的对象
None、True和False- 整数、浮点数、复数
- str、byte、bytearray
- 只包含可封存对象的集合,包括 tuple、list、set 和 dict
- 定义在模块最外层的函数(使用 def 定义,lambda 函数则不可以)
- 定义在模块最外层的内置函数
- 定义在模块最外层的类
__dict__属性值或__getstate__()函数的返回值可以被序列化的类(详见官方文档的Pickling Class Instances)
pickle反序列化漏洞
在上一节中,我们提到了Pickle中一个不安全的因素——反序列化未知的二进制字节流。原因是该字节流可能包含被精心构造的恶意代码,此时如果我们使用pickle.loads()方法unpickling,就会导致恶意代码的执行
1 | |
我在Person类中加入了__reduce__函数,该函数能够定义该类的二进制字节流被反序列化时进行的操作。如果返回值是一个(callable, ([para1,para2...])[,...])类型的元组,那么当字节流被反序列化时,Python就会执行callable(para1,para2...)函数。因此当上述的Person对象被unpickling时,就会执行os.system(command),结果如下
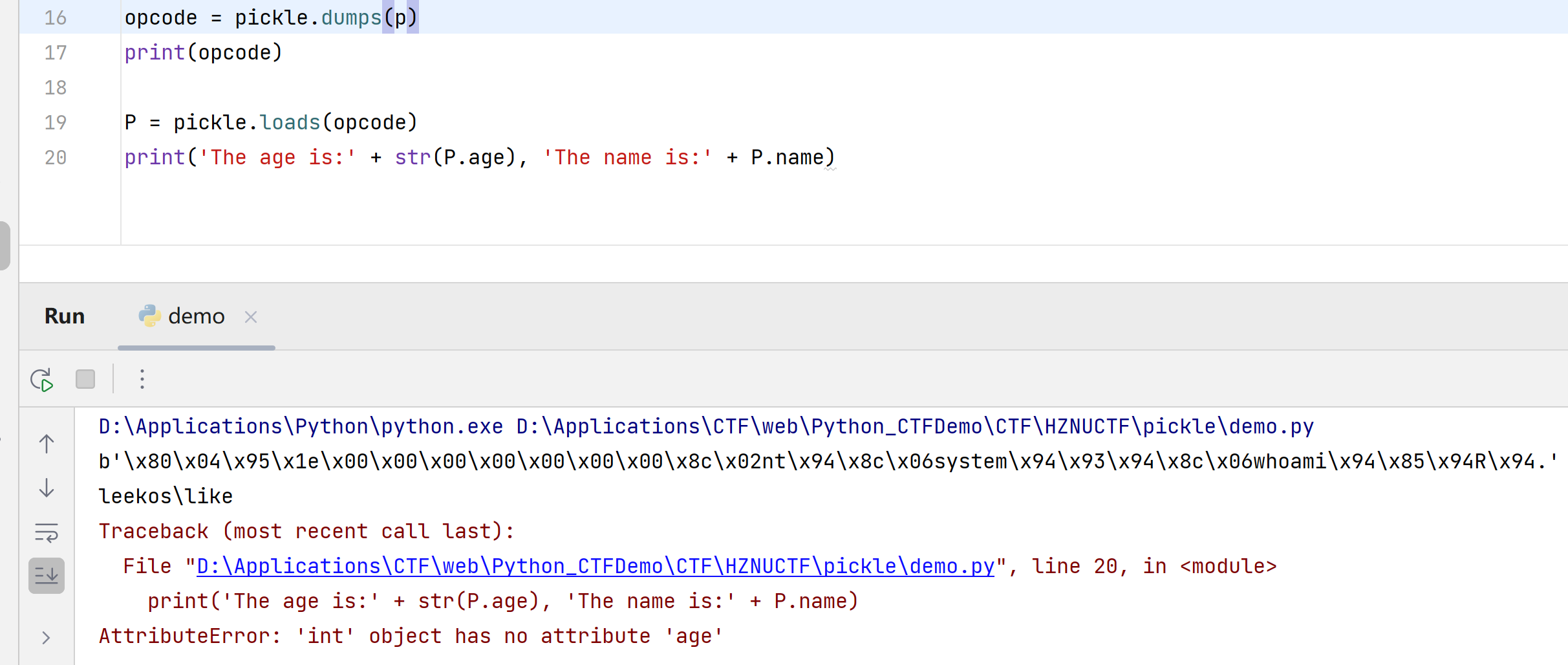
在python2中以字符串的形式进行转换时,这些序列化的字符串是什么意思,又按照什么规则生成的,这就涉及到了PVM,因为它是Python序列化过程和反序列化过程中最根本的东西。
pickle的作用
对于Python而言,它可以直接从源代码运行程序。Python解释器会将源代码编译为字节码,然后将编译后的字节码转发到Python虚拟机中执行。总的来说,PVM的作用便是用来解释字节码的解释引擎。
pickle执行流程
当运行Python程序时,PVM会执行两个步骤。
PVM会把源代码编译成字节码
字节码是Python特有的一种表现形式,不是二进制机器码,需要进一步编译才能被机器执行 . 如果 Python 进程在主机上有写入权限 , 那么它会把程序字节码保存为一个以 .pyc 为扩展名的文件 . 如果没有写入权限 , 则 Python 进程会在内存中生成字节码 , 在程序执行结束后被自动丢弃 .
Python进程会把编译好的字节码转发到PVM(Python虚拟机)中,PVM会循环迭代执行字节码指令,直到所有操作被完成。
pickle工作原理
Pickle是一门基于栈的编程语言 , 有不同的编写方式 , 其本质就是一个轻量级的 PVM .
其实pickle可以看作是一种独立的栈语言,它由一串串opcode(指令集)组成。该语言的解析是依靠Pickle Virtual Machine (PVM)进行的。
PVM由以下三部分组成
- 指令处理器( Instruction processor ):从流中读取
opcode操作码 和参数,并对其进行解释处理,不断改变stack和memo区域的值。重复这个动作,直到遇到.这个结束符后停止。 最终留在栈顶的值将被作为反序列化对象返回。 - 栈区(stack):由
Python的列表(list)实现 , 作为流数据处理过程中的暂存区 , 在不断的进出栈过程中完成对数据流的反序列化操作,并最终在栈顶生成反序列化的结果 - 标签区(memo):由
Python的字典(dict)实现 , 可以看作是数据索引或者标记 , 为 PVM 的整个生命周期提供存储功能 .简单来说就是将反序列化完成的数据以key-value的形式储存在memo中,以便使用。

当前用于 pickling 的协议共有 5 种。使用的协议版本越高,读取生成的 pickle 所需的 Python 版本就要越新。
- v0 版协议是原始的“人类可读”协议,并且向后兼容早期版本的 Python。
- v1 版协议是较早的二进制格式,它也与早期版本的 Python 兼容。
- v2 版协议是在 Python 2.3 中引入的。它为存储 new-style class 提供了更高效的机制。欲了解有关第 2 版协议带来的改进,请参阅 PEP 307。
- v3 版协议添加于 Python 3.0。它具有对
bytes对象的显式支持,且无法被 Python 2.x 打开。这是目前默认使用的协议,也是在要求与其他 Python 3 版本兼容时的推荐协议。 - v4 版协议添加于 Python 3.4。它支持存储非常大的对象,能存储更多种类的对象,还包括一些针对数据格式的优化。有关第 4 版协议带来改进的信息,请参阅 PEP 3154。
pickle协议是向前兼容的,0号版本的字符串可以直接交给pickle.loads(),不用担心引发什么意外。下面我们以V0版本为例,介绍一下常见的opcode
常用opcode**
在Python的pickle.py中,我们能够找到所有的opcode及其解释,常用的opcode如下,这里我们以V0版本为例
| 指令 | 描述 | 具体写法 | 栈上的变化 |
|---|---|---|---|
| c | 获取一个全局对象或import一个模块 | c[module]\n[instance]\n | 获得的对象入栈 |
| o | 寻找栈中的上一个MARK,以之间的第一个数据(必须为函数)为callable,第二个到第n个数据为参数,执行该函数(或实例化一个对象) | o | 这个过程中涉及到的数据都出栈,函数的返回值(或生成的对象)入栈 |
| i | 相当于c和o的组合,先获取一个全局函数,然后寻找栈中的上一个MARK,并组合之间的数据为元组,以该元组为参数执行全局函数(或实例化一个对象) | i[module]\n[callable]\n | 这个过程中涉及到的数据都出栈,函数返回值(或生成的对象)入栈 |
| N | 实例化一个None | N | 获得的对象入栈 |
| S | 实例化一个字符串对象 | S’xxx’\n(也可以使用双引号、'等python字符串形式) | 获得的对象入栈 |
| V | 实例化一个UNICODE字符串对象 | Vxxx\n | 获得的对象入栈 |
| I | 实例化一个int对象 | Ixxx\n | 获得的对象入栈 |
| F | 实例化一个float对象 | Fx.x\n | 获得的对象入栈 |
| R | 选择栈上的第一个对象作为函数、第二个对象作为参数(第二个对象必须为元组),然后调用该函数 | R | 函数和参数出栈,函数的返回值入栈 |
| . | 程序结束,栈顶的一个元素作为pickle.loads()的返回值 | . | 无 |
| ( | 向栈中压入一个MARK标记 | ( | MARK标记入栈 |
| t | 寻找栈中的上一个MARK,并组合之间的数据为元组 | t | MARK标记以及被组合的数据出栈,获得的对象入栈 |
| ) | 向栈中直接压入一个空元组 | ) | 空元组入栈 |
| l | 寻找栈中的上一个MARK,并组合之间的数据为列表 | l | MARK标记以及被组合的数据出栈,获得的对象入栈 |
| ] | 向栈中直接压入一个空列表 | ] | 空列表入栈 |
| d | 寻找栈中的上一个MARK,并组合之间的数据为字典(数据必须有偶数个,即呈key-value对) | d | MARK标记以及被组合的数据出栈,获得的对象入栈 |
| } | 向栈中直接压入一个空字典 | } | 空字典入栈 |
| p | 将栈顶对象储存至memo_n | pn\n | 无 |
| g | 将memo_n的对象压栈 | gn\n | 对象被压栈 |
| 0 | 丢弃栈顶对象 | 0 | 栈顶对象被丢弃 |
| b | 使用栈中的第一个元素(储存多个属性名: 属性值的字典)对第二个元素(对象实例)进行属性设置 | b | 栈上第一个元素出栈 |
| s | 将栈的第一个和第二个对象作为key-value对,添加或更新到栈的第三个对象(必须为列表或字典,列表以数字作为key)中 | s | 第一、二个元素出栈,第三个元素(列表或字典)添加新值或被更新 |
| u | 寻找栈中的上一个MARK,组合之间的数据(数据必须有偶数个,即呈key-value对)并全部添加或更新到该MARK之前的一个元素(必须为字典)中 | u | MARK标记以及被组合的数据出栈,字典被更新 |
| a | 将栈的第一个元素append到第二个元素(列表)中 | a | 栈顶元素出栈,第二个元素(列表)被更新 |
| e | 寻找栈中的上一个MARK,组合之间的数据并extends到该MARK之前的一个元素(必须为列表)中 | e | MARK标记以及被组合的数据出栈,列表被更新 |
这些指令很重要,是学懂opcode编写的基础
PVM工作流程
- PVM解析
str的过程

- PVM解析
__reduce__()的过程

举例
我们这里举一个简单的例子
1 | |
输出:
1 | |
分析:
1 | |
pickletools
我们可以使用pickletools模块,将opcode转化成方便我们阅读的形式,如下所示
1 | |
漏洞利用方式
命令执行
在上文我们已经提到了,我们可以通过在类中重写__reduce__方法,从而在反序列化时执行任意命令,但是通过这种方法一次只能执行一个命令,如果想一次执行多个命令,就只能通过手写opcode的方式了。
在opcode中,.是程序结束的标志。我们可以通过去掉.来将两个字节流拼接起来
1 | |
当然,在pickle中,和函数执行的字节码有三个:R、i、o,所以我们可以从三个方向构造paylaod
R指令
| R | 选择栈上的第一个对象作为函数、第二个对象作为参数(第二个对象必须为元组),然后调用该函数 | R | 函数和参数出栈,函数的返回值入栈 |
|---|---|---|---|
1 | |
o指令
| o | 寻找栈中的上一个MARK,以之间的第一个数据(必须为函数)为callable,第二个到第n个数据为参数,执行该函数(或实例化一个对象) | o | 这个过程中涉及到的数据都出栈,函数的返回值(或生成的对象)入栈 |
|---|---|---|---|
1 | |
i指令
| i | 相当于c和o的组合,先获取一个全局函数,然后寻找栈中的上一个MARK,并组合之间的数据为元组,以该元组为参数执行全局函数(或实例化一个对象) | i[module]\n[callable]\n | 这个过程中涉及到的数据都出栈,函数返回值(或生成的对象)入栈 |
|---|---|---|---|
1 | |
注意
部分Linux系统下和Windows下的opcode字节流并不兼容,比如Windows下执行系统命令函数为os.system(),在部分Linux下则为posix.system()。
并且pickle.loads会解决import 问题,对于未引入的module会自动尝试import。也就是说整个python标准库的代码执行、命令执行函数我们都可以使用。
实例化对象
实例化对象也是一种特殊的函数执行,我们同样可以通过手写opcode来构造
1 | |
以上opcode相当于手动执行了构造函数Person(20,'leekos')。
变量覆盖
在session或token中,由于需要存储一些用户信息,所以我们常常能够看见pickle的身影。程序会将用户的各种信息序列化并存储在session或token中,以此来验证用户的身份。
假如session或token是以明文的方式进行存储的,我们就有可能通过变量覆盖的方式进行身份伪造。
b 使用栈中的第一个元素(储存多个属性名: 属性值的字典)对第二个元素(对象实例)进行属性设置 b 栈上第一个元素出栈
d 寻找栈中的上一个MARK,并组合之间的数据为字典(数据必须有偶数个,即呈key-value对) d MARK标记以及被组合的数据出栈,获得的对象入栈
1 | |
1 | |
首先哦通过c来获取__main__.secret模块,然后将字符串name、hacker压入栈中,通过操作码d将两个字符串组成字典{'name':'hacker'}形式,压入栈中。由于在pickle中,反序列化后的数据会以key-value的形式存储,所以secret模块中的变量name="leekos",是以{'name':'leekos'}形式存储的。最后通过操作码b来执行__dict__.update()即{'name':'leekos'}.update({'name':'hacker'}),因此最终name变量的值被覆盖为了hacker
__dict__.update()是一个字典对象的方法,用于将另一个字典或键值对添加到当前字典中。
官方修复建议
对于pickle反序列化漏洞,官方的第一个建议就是永远不要unpickle来自于不受信任的或者未经验证的来源的数据。第二个就是通过重写Unpickler.find_class()来限制全局变量,我们来看官方的例子
1 | |
以上例子通过重写Unpickler.find_class()方法,限制调用模块只能为builtins,且函数必须在白名单内,否则抛出异常。这种方式限制了调用的模块函数都在白名单之内,这就保证了Python在unpickle时的安全性。
不过,假如Unpickler.find_class()中对于模块和函数的限制不是那么严格的话,我们仍然有可能绕过其限制。
绕过RestrictedUnpickler限制
想要绕过find_class,我们则需要了解其何时被调用。在官方文档中描述如下
出于这样的理由,你可能会希望通过定制
Unpickler.find_class()来控制要解封的对象。 与其名称所提示的不同,Unpickler.find_class()会在执行对任何全局对象(例如一个类或一个函数)的请求时被调用。 因此可以完全禁止全局对象或是将它们限制在一个安全的子集中。
在opcode来看,
c、i、\x93这三个字节码与全局对象有关,当出现这三个字节码时会调用find_class,当我们使用这三个字节码时不违反其限制即可。从python代码来看,
find_class()只会在解析opcode时调用一次,所以只要绕过opcode执行过程,find_class()就不会再调用,也就是说find_class()只需要过一次,通过之后再产生的函数在黑名单中也不会拦截,所以可以通过__import__绕过一些黑名单。
绕过builtins
在一些例子中,我们常常会见到module=="builtins"这一限制,比如官方文档中的例子,只允许我们导入builtins这一模块
1 | |
那么什么是builtins模块呢?
当我们启动Python之后,即使没有创建任何的变量或者函数,还是会有许多函数可以使用,如:
1 | |
上述这类函数被我们称为”内置函数”,这其实就是builtins模块的功劳,这些内置函数都是包含在builtins模块内的。而Python解释器在启动时已经自动帮我们导入了builtins模块,所以我们自然就可以使用这些内置函数了。
我们可以通过for i in sys.modules['builtins'].__dict__:print(i)来查看该模块中包含的所有模块函数等,大致如下:

假如内置函数中一些执行命令的函数也被禁用了,而我们仍想命令执行,那么漏洞的利用思路就类似于Python中的沙箱逃逸。
Code-Breaking2018 picklecode
我们来举一个例子:
1 | |
题目将pickle能够引入的模块限定为builtins,并且设置了子模块黑名单:{'eval', 'exec', 'execfile', 'compile', 'open', 'input', '__import__', 'exit'},于是我们能够直接利用的模块有:
builtins模块中,黑名单外的子模块。- 已经
import的模块:io、builtins(需要先利用builtins模块中的函数)
由于黑名单中没有getattr(),所以可以通过getattr()获取io或builtins的子模块以及子模块的子模块,而builtins有eval、exec等危险函数,即使在黑名单中,也可以通过getattr获得。
代码没有禁用getattr()函数,getattr可以获取对象的属性值。因此我们可以通过builtins.getattr(builtins,'eval')的形式来获取eval函数
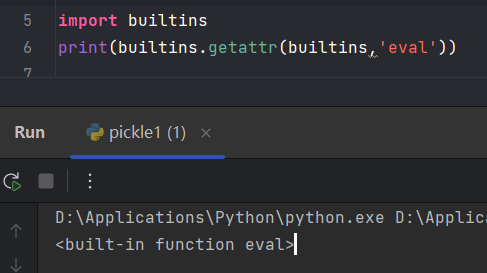
接下来我们得构造出一个builtins模块来传给getattr的第一个参数,
我们可以使用builtins.globals()函数获取builtins模块包含的内容:__builtins__

发现builtins.globals()中有builtins模块,但是这是在字典中,我们需要使用字典dict的get()函数获取它
所以最终的payload就是:
1 | |
接下来就需要构造opcode了,首先获取get()函数
1 | |
然后获取globals字典:
) 向栈中直接压入一个空元组 ) 空元组入栈
1 | |
现在我们有了get(),有了globals()字典,把他们组合起来我们就能够获取builtins模块了:
1 | |
最后使用获取到的builtins模块,通过getattr()获取eval()函数即可:
1 | |
绕过R指令
倘若将字节码R也禁用了,那我们怎么进行RCE呢?
如果你还记得我上文所说的pickle漏洞命令执行的几种方法的话,你肯定能立即想到和函数执行有关的字节码R、i、o。实际上,如果没有R指令,我们同样能够进行函数执行。有下面这样一个例子
1 | |
1 | |
这里禁用了R指令,但是我们仍有方法初始化一个Animal对象。我在上文提到过,使用R指令实例化对象的过程,实际上就是调用构造函数的过程,本质上也是函数执行,所以我们同样能够使用其他指令绕过。
i指令
相当于c和o的组合,先获取一个全局函数,然后寻找栈中的上一个MARK,并组合之间的数据为元组,以该元组为参数执行全局函数(或实例化一个对象)
1 | |
o指令
寻找栈中的上一个MARK,以之间的第一个数据(必须为函数)为callable,第二个到第n个数据为参数,执行该函数(或实例化一个对象)
1 | |

假如这里我们不知道stao模块的内容,我们可以通过变量覆盖的方式将原有stao中的变量覆盖掉。
1 | |

b指令
其实我们在上文已经使用过了b指令,当时他的作用是用来更新栈上的一个字典进行变量覆盖。实际上官方对它的解释是BUILD,当PVM解析到b指令时执行__setstate__或者__dict__.update()。
1 | |
例子:
1 | |
那么这有什么安全问题呢?如果我们将字典
{"__setstate__":os.system},压入栈中,并执行b字节码,,由于此时并没有__setstate__,所以这里b字节码相当于执行了__dict__.update,向对象的属性字典中添加了一对新的键值对。如果我们继续向栈中压入命令command,再次执行b字节码时,由于已经有了__setstate__,所以会将栈中字节码b的前一个元素当作state,执行__setstate__(state),也就是os.system(command)。
Payload如下
1 | |
绕过关键字过滤
在某些情况下,假如我们想利用opcode进行变量覆盖从而进行身份伪造,但是代码中过滤了我们想要覆盖的属性关键字,我们怎么绕过呢?
利用V指令进行Unicode绕过
V指令的用法如下,类似于指令S
S 实例化一个字符串对象 S’xxx’\n(也可以使用双引号、'等python字符串形式) 获得的对象入栈 V 实例化一个UNICODE字符串对象 Vxxx\n 获得的对象入栈
V指令可以识别Unicode编码,假如admin被过滤,那么可以做如下替换:
1 | |
十六进制绕过
操作码S也能够识别十六进制字符串,可以构造如下:
1 | |
利用内置函数获取关键字
对于已导入的模块,我们可以通过sys.modules['xxx']来获取该模块,然后通过内置函数dir()来列出模块中的所有属性
1 | |
可以看到模块中的属性是以列表的形式输出,且我们所需的字符串secret位于列表末尾。
由于pickle不支持列表索引、字典索引,所以我们不能直接获取所需的字符串。在Python中,我们可以通过reversed()函数来将列表逆序,并返回一个迭代对象
然后我们可以通过next()函数来获取迭代对象的下一个元素,默认从第一个元素开始。最终可以构造如下:
1 | |
参考文章
https://goodapple.top/archives/1069
https://xz.aliyun.com/t/7436#toc-12
https://www.freebuf.com/articles/web/252189.html
https://www.leavesongs.com/PENETRATION/code-breaking-2018-python-sandbox.html