Linux操作系统笔记
本文最后更新于:2023年12月29日 上午
Linux操作系统笔记
文件与目录基本操作
文件名长度
• 一般允许1-255个字符
• 有些UNIX不支持长文件名,但至少支持1-14个字符
取名的合法字符
• 除斜线(“/“)外的所有字符都是命名的合法字符
• 不可打印字符也可以做文件名(除了字节0)
• 斜线(“/“)留作路径名分隔符
• 建议文件名中只包含字母、数字和下划线
touch命令
touch 是一个在 Unix 和类 Unix 操作系统中常用的命令,用于创建空文件或者更新文件的访问和修改时间戳。以下是 touch 命令的基本用法和选项:
基本用法:
1 | |
选项:
-a,–time=atime,–time=access,–time=use:只更改访问时间。
1
touch -a filename-c,–no-create:不创建任何文件。
1
touch -c filename-d,–date=字符串:使用指定的日期时间字符串,而不是当前时间。
1
touch -d "2023-01-01 12:00:00" filename-m,–time=mtime,–time=modification:只更改修改时间。
1
touch -m filename-t,–time=时间戳:使用指定的时间戳,格式为
[[CC]YY]MMDDhhmm[.ss]。1
touch -t 202301011200.00 filename–help:显示帮助信息。
1
touch --help–version:显示版本信息。
1
touch --version
示例:
创建一个新文件:
1
touch newfile.txt更改文件的访问和修改时间:
1
touch filename使用指定的日期时间字符串:
1
touch -d "2023-01-01 12:00:00" filename使用指定的时间戳:
1
touch -t 202301011200.00 filename只更新访问时间:
1
touch -a filename只更新修改时间:
1
touch -m filename
touch 命令的主要功能是更新文件的时间戳,但它也可以用来创建新文件,如果文件不存在的话。
mkdir命令
mkdir 是用于在 Unix 和类 Unix 操作系统中创建目录(文件夹)的命令。以下是 mkdir 命令的基本用法和选项:
基本用法:
1 | |
选项:
-m,–mode=模式:设置权限模式(类似于
chmod命令)。1
mkdir -m 755 mydirectory-p,–parents:递归创建目录,如果上层目录不存在也会创建。
1
mkdir -p /path/to/my/directory–help:显示帮助信息。
1
mkdir --help–version:显示版本信息。
1
mkdir --version
示例:
创建一个新目录:
1
mkdir mydirectory设置权限模式:
1
mkdir -m 755 mydirectory递归创建目录及其父目录:
1
mkdir -p /path/to/my/directory
mkdir 命令是创建目录的标准工具。通过指定目录名,您可以创建一个新的目录。如果要创建多级目录,可以使用 -p 选项,这样如果上层目录不存在,也会被创建。
cp命令
1 | |
mv命令
mv 命令是在 Unix 和类 Unix 操作系统中用于移动或重命名文件或目录的命令。以下是 mv 命令的基本用法和选项:
基本用法:
1 | |
移动文件到另一个目录:
1
mv file.txt /path/to/destination/重命名文件:
1
mv oldfile.txt newfile.txt移动并覆盖目标文件(无提示):
1
mv -f source.txt /path/to/destination/移动文件并为目标文件创建备份:
1
mv -b file.txt /path/to/backup/交互式地移动文件,避免覆盖目标文件:
1
mv -i file.txt /path/to/destination/仅在源文件较新或目标文件不存在时执行移动操作:
1
mv -u file.txt /path/to/destination/
mv 命令不仅可以用于移动文件,还可以用于重命名文件。其选项提供了一些额外的控制,例如备份、强制覆盖和交互式提示等。
rm命令
1 | |
rmdir命令
1 | |
wc命令
wc(word count)命令是用于计算文件中字数、行数和字符数的命令。
基本用法:
1 | |
选项:
-c,–bytes: 打印文件的字节数。
1
wc -c filename-w,–words: 打印文件的字数。
1
wc -w filename-l,–lines: 打印文件的行数。
1
wc -l filename–help: 显示帮助信息。
1
wc --help–version: 显示版本信息。
1
wc --version
示例:
计算文件的字节数、字数和行数:
1
wc filename只显示文件的字节数:
1
wc -c filename只显示文件的字数:
1
wc -w filename只显示文件的行数:
1
wc -l filename同时统计多个文件的字节数、字数和行数:
1
wc file1.txt file2.txt
搜索文件
find命令
find 命令是查找文件和目录的命令。它支持强大的搜索功能,
基本用法:
1 | |
常见选项和条件:
-name “模式”: 按文件名进行匹配,可以使用通配符。
1
find /path/to/search -name "*.txt"-type 类型: 按文件类型进行匹配,如
f表示文件,d表示目录。1
find /path/to/search -type f-size [+/-]大小: 按文件大小进行匹配,加号表示大于,减号表示小于,没有符号表示等于。
1
find /path/to/search -size +1M-mtime [+/-]天数: 按文件修改时间进行匹配,加号表示更早,减号表示更近。
1
find /path/to/search -mtime -7-exec 命令 {} ;: 对匹配到的文件执行指定的命令。
1
find /path/to/search -name "*.log" -exec rm {} \;-print: 将匹配到的文件路径打印到标准输出。
1
find /path/to/search -name "*.txt" -print-maxdepth 深度: 限制查找的最大深度。
1
find /path/to/search -name "*.txt" -maxdepth 2-mindepth 深度: 限制查找的最小深度。
1
find /path/to/search -name "*.txt" -mindepth 2
示例:
查找所有以
.txt结尾的文件:1
find /path/to/search -name "*.txt"查找文件并执行操作(例如删除):
1
find /path/to/search -name "*.log" -exec rm {} \;查找指定类型的文件:
1
find /path/to/search -type f查找大于 1MB 的文件:
1
find /path/to/search -size +1M查找最近 7 天内修改过的文件:
1
find /path/to/search -mtime -7
xargs
xargs 是一个命令,用于从标准输入或者其他命令的输出中读取数据,并将其作为参数传递给指定的命令。xargs 可以帮助处理由其他命令生成的大量输入,并将其转换为命令行参数。
基本用法:
1 | |
常见选项:
-0,–null: 使用空字符(null)作为定界符,用于处理文件名中可能包含空格等特殊字符的情况。
1
find /path/to/files -type f -print0 | xargs -0 rm-n 数目,–max-args=数目: 指定每个命令行调用使用的参数的最大数目。
1
ls | xargs -n 2-i,–replace[=替代字符串]: 使用替代字符串替代命令中的
{},或者使用指定的替代字符串。1
echo "file1 file2 file3" | xargs -i cp {} /destination/path-p,–interactive: 在执行命令之前,提示用户确认是否继续。
1
find /path/to/files -type f | xargs -p rm–help: 显示帮助信息。
1
xargs --help–version: 显示版本信息。
1
xargs --version
示例:
使用
xargs将文件列表传递给rm命令删除文件:1
find /path/to/files -name "*.txt" | xargs rm使用
-exec与xargs结合,删除大量文件:1
find /path/to/files -name "*.log" -exec rm {} +使用
xargs处理包含空格的文件名:1
find /path/to/files -type f -print0 | xargs -0 rm使用
xargs交互式地执行命令:1
find /path/to/files -name "*.tmp" | xargs -p rm使用
-i替代字符串:1
echo "file1 file2 file3" | xargs -i cp {} /destination/path
find与xargs协作
1 | |
压缩和解压缩文件
1. tar 命令(打包/解包)
打包文件或目录:
1
tar -cvf archive.tar file1 file2 directory1解包文件:
1
tar -xvf archive.tar打包并压缩(使用 gzip):
1
tar -czvf archive.tar.gz file1 file2 directory1解压缩并解包(使用 gzip):
1
tar -xzvf archive.tar.gz
2. gzip 和 gunzip 命令
压缩文件:
1
gzip filename解压缩文件:
1
gunzip filename.gz
3. bzip2 和 bunzip2 命令
压缩文件:
1
bzip2 filename解压缩文件:
1
bunzip2 filename.bz2
4. zip 和 unzip 命令
压缩文件或目录:
1
zip archive.zip file1 file2 directory1解压缩文件或目录:
1
unzip archive.zip
示例:
使用 tar 打包和解包:
1
2
3
4
5# 打包
tar -cvf archive.tar file1 file2 directory1
# 解包
tar -xvf archive.tar使用 tar 打包并压缩(gzip):
1
2
3
4
5# 打包并压缩
tar -czvf archive.tar.gz file1 file2 directory1
# 解压缩并解包
tar -xzvf archive.tar.gz使用 gzip 进行压缩和解压缩:
1
2
3
4
5# 压缩
gzip filename
# 解压缩
gunzip filename.gz使用 bzip2 进行压缩和解压缩:
1
2
3
4
5# 压缩
bzip2 filename
# 解压缩
bunzip2 filename.bz2使用 zip 进行压缩和解压缩:
1
2
3
4
5# 压缩
zip archive.zip file1 file2 directory1
# 解压缩
unzip archive.zip
分割与合并文件
split
有时网站、U盘等对文件大小有限制,需要把大文件 拆分成更小的文件。
1 | |
过滤器
0x01.grep 行过滤
grep可以过滤行
grep选项:
-i忽略大小写-n添加行号-v反向过滤,grep -v 'abc' myfile过滤出除了有abc的行-c记录出符合的行中总字符数
基本正则表达式 grep
. 表示单个任意字符(换行符除外)
[…] 表示单个括号中的任意字符
x* 表示x出现0次或0次以上
^x 锚定行首字符x,其中^代表行首
x$ 锚定行尾字符x,其中$代表行尾
扩展正则表达式 egrep
grep默认把 ERE 元字符按普通字符处理,在其 前面有反斜杠时才按元字符处理,这一点正好与 扩展正则表达式元字符相反!
扩展正则表达式元字符 : ?、+、|、{ }、( )
• grep -E
• egrep
x+ 表示 x 出现 1 次以上
1 | |
x? 表示 x 出现 0 次或 1 次
1 | |
x|y 表示 x 或 y
1 | |
x{n} 表示 x 正好出现 n 次
x{n,} 表示 x 出现 n 次以上
x{m,n} 表示 x 出现 m 到 n 次 (m<n)
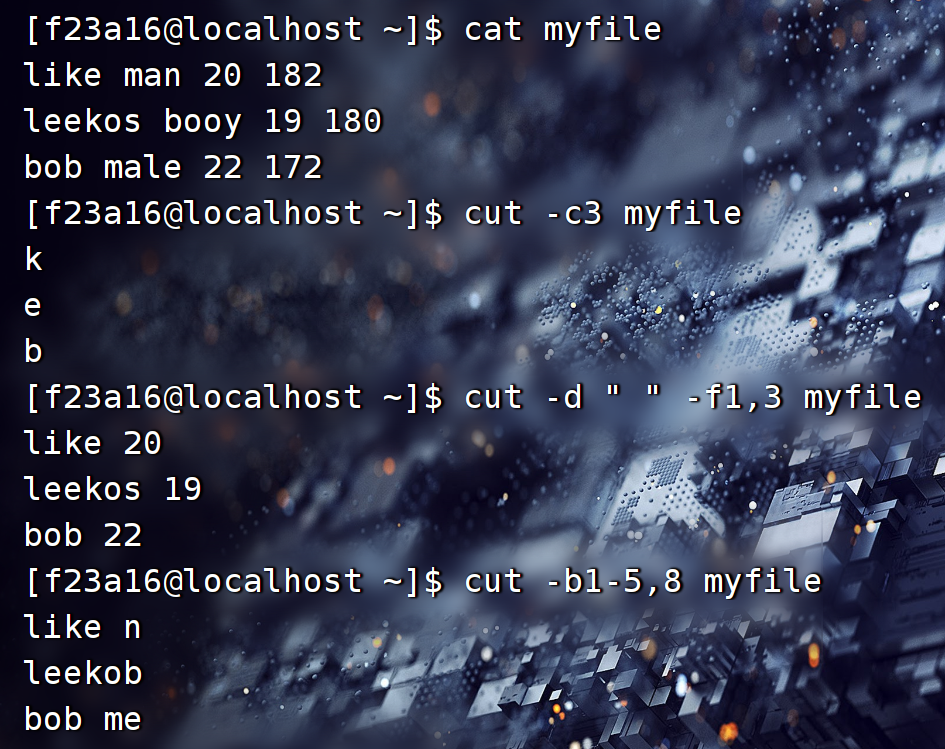
0x02.cut 列过滤
cut可以过滤列,
cut选项:
- -c 指定提取的字符列表,-c3 表示提取每列的第3个字符
- -f 提取指定的字段列表 ,-f1,3 表示提取第1和第3个字段
- -d 指定字段的分隔符,
-d ','以逗号分隔字段 - -b 按字节位置提取文件内容,可以指定一个范围
0x03.tr 字符转换
tr只能通过stdin标准输入
小写转大写
1 | |
空格转tab
1 | |
tr -d 删除字符
1 | |
tr -c 取反
tr -c 可以进行取指定字符的补集,类似正则的^
1 | |
tr -s 压缩重复字符
1 | |
0x04.sort 排序
sort命令用于对文本文件的行进行排序操作。它可以按照不同的排序规则和顺序对行进行排序,并将结果输出到标准输出或指定的文件中。
以下是sort命令的一些常见选项:
-r, --reverse:以逆序排序,即降序排序。-n, --numeric-sort:按照数值进行排序而不是按照字典顺序。适用于包含数值的行。-f, --ignore-case:在排序时忽略大小写,即不区分大小写进行排序。-u, --unique:去除重复的行,仅保留唯一的行。-k, --key=KEYDEF:按照指定的键定义进行排序。可以指定多个键定义以进行复合排序。-t, --field-separator=SEP:指定字段分隔符。默认情况下,字段分隔符是空白字符(空格或制表符)。
1 | |
1 | |
sort -r -t -k
- -r 降序排列
- -t 指定字段分隔符
- -k 指定排序字段
1 | |
sort -k -n
- -n 以数值大小排序,而不是以字典排序
- -k 指定排序字段,加小数点,表示从第几位开始算
sort -n -t^ -k4.2 booklist
-n表示以数值大小排序,-k4.2表示以第4个字段的第2位排序
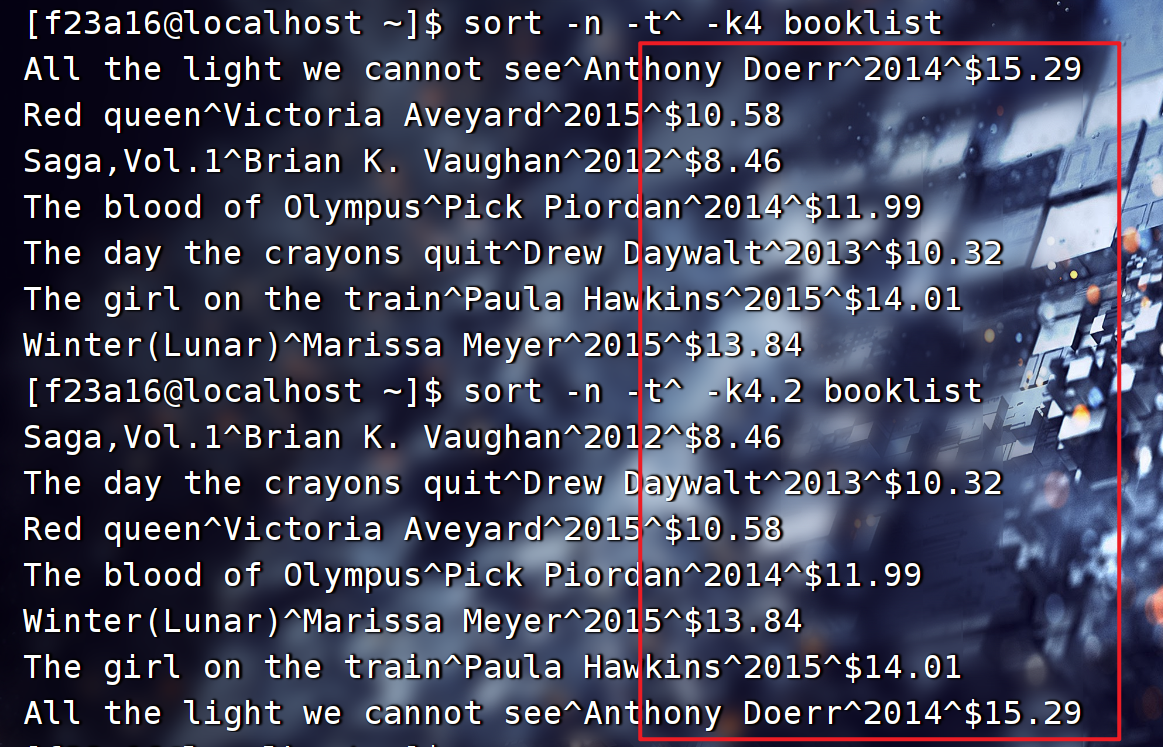
sort 可通过多个-k多列排序

-k1.3,1.4:这个键定义表示按照第一个字段的第三个字符和第四个字符进行排序。它将会对这个范围内的字符进行排序,而忽略其他字符。-k3nr:这个键定义表示按照第三个字段进行逆序排序。n选项指示对字段进行数值排序,r选项表示逆序排序。-k2nr:这个键定义表示按照第二个字段进行逆序排序,同样使用了n选项进行数值排序和r选项进行逆序排序。
整个命令的作用是首先按照第一个字段的第三个和第四个字符进行排序,然后在相同的排序结果中,按照第三个字段进行逆序排序,最后在相同的排序结果中,按照第二个字段进行逆序排序。
0x05.uniq
-c, --count:在输出中显示每行重复出现的次数。-d, --repeated:仅显示重复的行。-u, --unique:仅显示不重复的行。-i, --ignore-case:在比较行时忽略大小写。-f, --skip-fields=N:跳过前面的 N 个字段,仅考虑从第 N+1 个字段开始的内容。-s, --skip-chars=N:跳过前面的 N 个字符,仅考虑从第 N+1 个字符开始的内容。
1 | |
sed
sed是一种流编辑器(stream editor),在Unix和类Unix系统中广泛使用。它用于处理文本流,可以在读取输入流时对文本进行转换和编辑,然后将结果输出到标准输出流。
sed通过一系列编辑命令来实现对文本的处理。这些命令可以用于插入、删除、替换和转换文本,以及执行其他各种编辑操作。sed的编辑命令可以通过脚本文件或命令行直接提供。
sed命令格式
1 | |
-e 可以用来执行多个脚本,-f代表从脚本文件中执行脚本
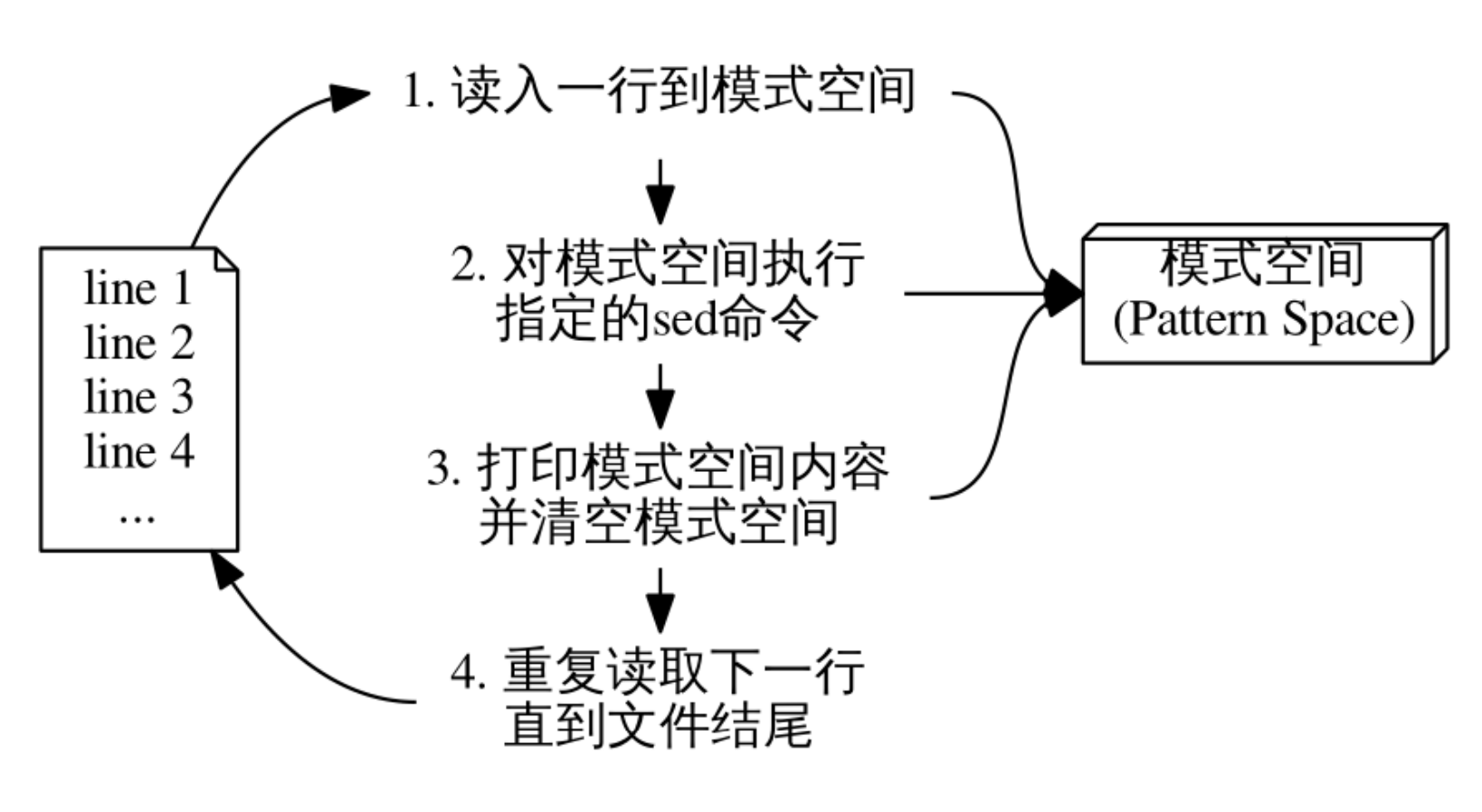
sed工作原理
sed从输入流中逐行读取文本。- 对于每一行,
sed检查是否有与之匹配的编辑命令。 - 如果有匹配的命令,
sed执行该命令对文本进行转换和编辑。 sed将转换后的文本输出到标准输出流。- 重复步骤2到步骤4,直到处理完所有的输入行
sed常用选项
-n:禁止自动打印模式空间内容。默认情况下,sed会将每一行的内容打印到标准输出流,但使用-n选项后,只有通过p命令显式指定打印的行才会被输出。-i:直接在原始文件中进行编辑,即原地修改文件。使用此选项后,sed会将编辑后的结果直接写回到原始文件中,而不是将结果输出到标准输出流。-e script:在命令行中指定编辑脚本。使用此选项可以直接在命令行中提供一系列编辑命令,而不是使用脚本文件。-f script-file:从指定的脚本文件中读取编辑命令。使用此选项可以将编辑命令保存在一个脚本文件中,然后通过-f选项指定该文件来执行编辑操作。-r:启用扩展正则表达式语法。默认情况下,sed使用基本正则表达式语法,但使用-r选项后,可以使用更强大的扩展正则表达式语法。-s:对每个输入文件分别处理。默认情况下,sed会将所有输入文件视为单个连续的文本流进行处理,而使用-s选项后,sed会将每个输入文件视为独立的文本流进行处理。-u:即时刷新输出。默认情况下,sed会将输出缓冲起来,然后一次性输出。使用-u选项后,sed会立即刷新输出,以实现更及时的输出。
sed行选择
命令前面可以附加地址作为执行条件
1 | |
第n行:
选择第5行并打印:
1
sed '5p' file.txt
第m+kn行:
选择所有奇数行并打印:
1
sed '1~2p' file.txt选择所有3的倍数行并打印:
1
sed '1~3p' file.txt
末行:
选择末行并打印:
1
sed '$p' file.txt
与正则表达式re匹配的行:
选择包含单词”apple”的行并打印:
1
sed '/apple/p' file.txt
与正则表达式re匹配的行(使用%作为定界符):
选择以”example”开头的行并打印:
1
sed '\%^example%p' file.txt
不与正则表达式re匹配的行:
选择不包含单词”apple”的行并打印:
1
sed '/apple/!p' file.txt
sed范围选择
1 | |
当使用sed时,以下是使用给范围选择的示例:
从第m行至第n行:
选择从第3行到第7行并打印:
1
sed '3,7p' file.txt
从第n行往后至与正则表达式re匹配的第一行:
选择从第5行往后,直到遇到包含单词”apple”的第一行,并打印:
1
sed '5,/apple/p' file.txt
从匹配re1的行开始到匹配re2的第一行为止:
选择从包含”start”的行开始,一直到遇到包含”end”的第一行,并打印:
1
sed '/start/,/end/p' file.txt
从m~n行之外的行:
选择不在第2行到第5行范围内的行,并打印:
1
sed '2,5!p' file.txt
sed常用命令
#:注释命令,用于添加注释,对脚本没有实际影响。
示例:
1
sed 's/old/new/' file.txt # 替换文件中的字符串,忽略注释行
q:退出命令,用于在满足条件后退出sed的执行。示例:
1
sed '/pattern/q' file.txt # 匹配到指定模式后退出,并打印之前的内容
d:删除命令,用于删除模式空间的内容,并立即开始新的循环。示例:
1
sed '/pattern/d' file.txt # 删除包含指定模式的行
p:打印命令,用于打印模式空间的内容。
示例:
1
sed -n '2,5p' file.txt # 打印文件中第2行到第5行的内容
n:读取下一行命令,用于替换模式空间的内容为文件的下一行。示例:
1
sed -n '/start/,/end/p;n' file.txt
这个示例将打印位于”start”和”end”之间的行,并在打印后读取下一行。这样可以确保在每次打印匹配行后,都会继续处理下一行
{cmd1; cmd2; ...}:命令组,用于在地址匹配时执行多个命令。示例:
1
sed '/pattern/{s/foo/bar/; s/apple/orange/}' file.txt # 匹配到指定模式后执行多个替换操作
sed示例
1 | |
sed s命令
sed中的s命令是用于替换字符串的常见命令。它的语法为:
1 | |
其中,old是要替换的旧字符串,new是替换为的新字符串。s命令默认只替换每行中第一个匹配的字符串,如果要替换所有匹配的字符串,可以添加g标志(全局替换):
1 | |
以下是一些示例,展示了s命令的用法:
替换单个字符串:
将文件中的所有”apple”替换为”orange”:
1
sed 's/apple/orange/g' file.txt
使用正则表达式进行替换:
将文件中以”apple”开头的单词替换为”orange”:
1
sed 's/^apple/orange/g' file.txt
引用捕获组进行替换:
将文件中的日期格式”DD/MM/YYYY”替换为”YYYY-MM-DD”:
1
sed 's/\([0-9]\{2\}\)\/\([0-9]\{2\}\)\/\([0-9]\{4\}\)/\3-\2-\1/g' file.txt
替换特定行中的字符串:
只将第5行中的”apple”替换为”orange”:
1
sed '5s/apple/orange/g' file.txt
sed高级
N
- 读下一行
- 若读取失败则直接退出sed(不再执行其后的命令)
- 若读取成功则在模式空间尾部添加换行符\n,并将 新行附加在后面

P
打印模式空间内容至第一个换行符 (包括该换行符)

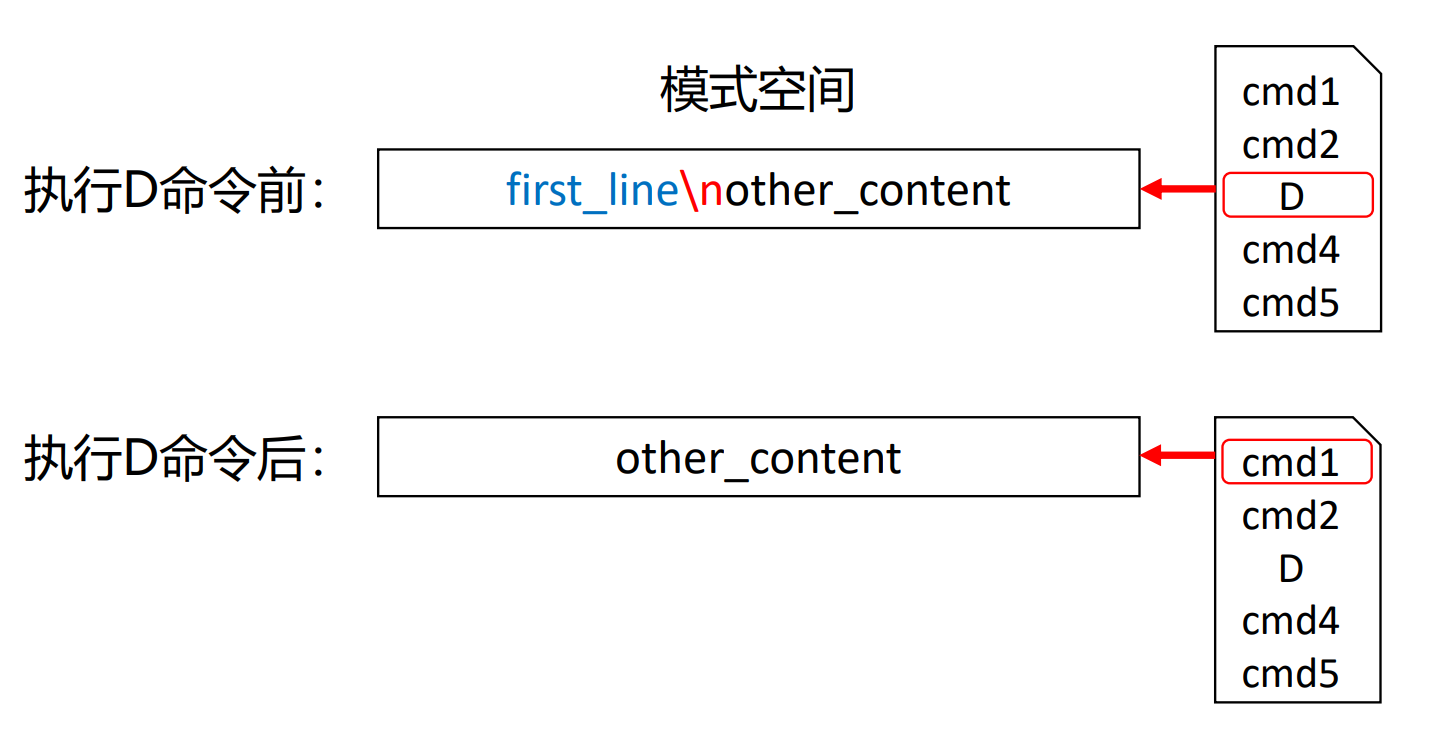
D
如果模式空间中不含\n,则与d命令相同,否则删除 模式空间中直到第一个\n的内容(包含该\n),然后对 模式空间中的剩余内容执行新一轮循环(不读入新行)
sed高级命令示例
1 | |
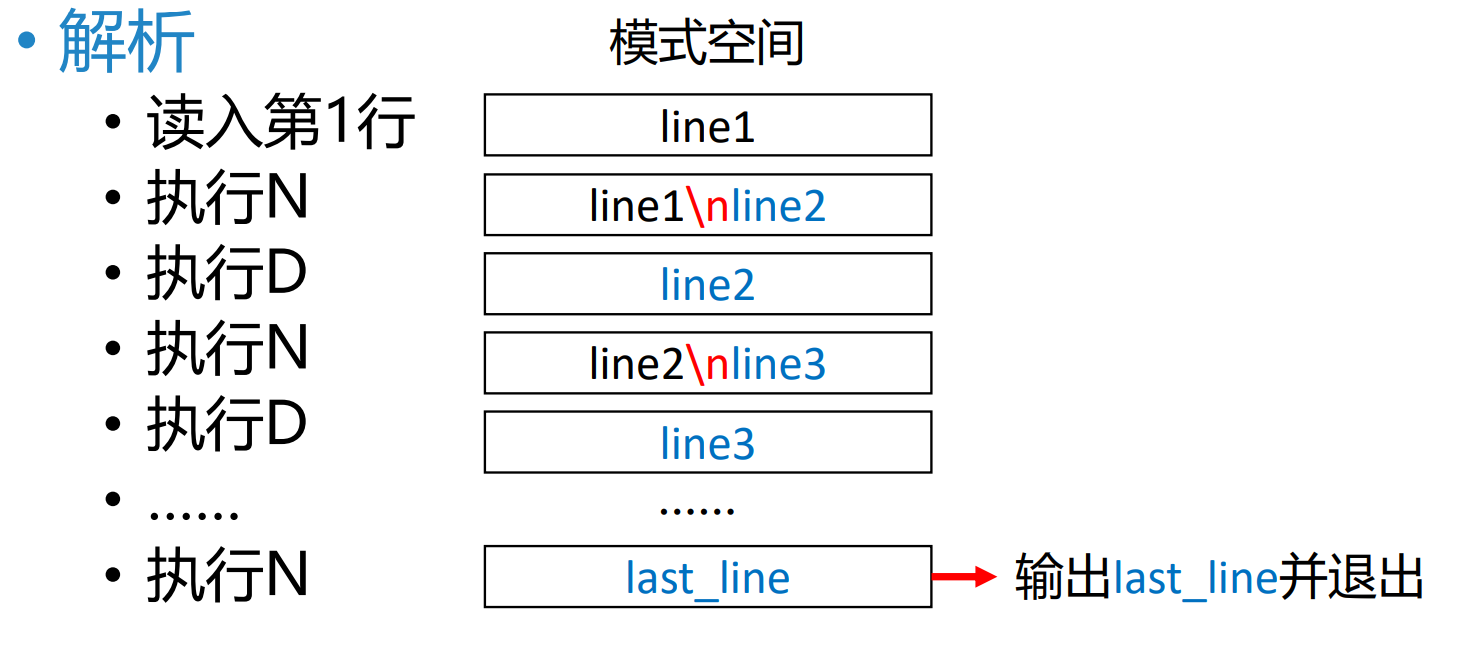
1 | |

sed空间
sed同时维护两个内存缓冲区
• 模式空间(pattern space)
• 保持空间(hold space),也译为暂存空间
模式空间
• 不断从输入获取新行
• 可通过sed脚本修改其内容
• 每次执行完sed脚本后会被清空(有些命令如D除外)
暂存空间
• 只能从模式空间获得内容
• 其内容既不能直接修改也不会自动被清空
• 其内容需导入模式空间后才能被修改
1 | |
sed流程控制
• 标签
1 | |
分支(branch)跳转
1 | |
测试(test)跳转
1 | |
awk
awk 是一种强大的文本处理工具,通常用于从文件或者输入流中抽取和处理数据。它是一种类似于编程语言的工具,用于按照指定的规则处理文本行。
基本用法
1 | |
- pattern: 模式,用于匹配文本行。
- action: 在匹配模式的情况下执行的操作。
示例
显示文件的第一列:
1
awk '{print $1}' filename.txt计算文件的总行数:
1
awk 'END {print NR}' filename.txt计算文件的总和:
1
awk '{sum += $2} END {print "Sum:", sum}' filename.txt查找并打印包含特定文本的行:
1
awk '/pattern/ {print}' filename.txt显示文件中每行的字符数:
1
awk '{print length($0)}' filename.txt过滤并打印满足条件的行:
1
awk '$3 > 50 {print}' filename.txt在列中查找最大值:
1
awk 'max < $2 {max = $2} END {print "Max value:", max}' filename.txt计算平均值并显示小数:
1
awk '{sum += $3} END {print "Average:", sum/NR}' filename.txt删除空白行:
1
awk NF filename.txt在特定列中查找并替换值:
1
awk '$4 == "old_value" {$4 = "new_value"} {print}' filename.txt逐行执行多个操作:
1
awk '{if ($2 > 50) {print $1 " Pass"} else {print $1 " Fail"}}' scores.txt按列合并两个文件:
1
awk 'NR==FNR{a[$1]=$2; next} {print $0, a[$1]}' file1.txt file2.txt在两个文件中查找并显示匹配行:
1
awk 'NR==FNR{a[$1]=$0; next} $1 in a {print a[$1], $0}' file1.txt file2.txt
用户组和权限管理
用户账户
用户帐号代表用户身份,具有唯一的UID
根账户(root)
• 超级用户root可以不受限制地执行所有任务
• UID:0
• 主目录:/root
系统账户
• 系统或应用程序使用的账户,供服务使用的也称服务账户
• UID:1-999、65534
• 主目录:各有不同
普通账户
• 供实际普通用户登录使用的账户
• UID:从1000开始顺序编号
• 主目录:/home/username
• 普通用户默认无法访问其他用户的主目录
用户配置文件
用户账户配置文件
/etc/passwd
- 存放除密码之外的账户信息
- 所有用户均可读取
- 记录格式:man 5 passwd
- 用户密码配置文件
/etc/shadow
- 存放与用户密码相关的信息
- CentOS 7默认使用sha512哈希算法加密用户口令
- 除root外,所有用户均无法读取
- 记录格式:man 5 shadow
组账户
组是用户的集合,具有唯一GID。可以以组为单位分配权限,则组内成员自动获得所分配权限
一个用户可以同时属于多个组
一个主要组(Primary Group),也叫初始组(InitialGroup),即用户的默认组,创建用户时默认会自动创建一个与用户同名的组作为其主要组(默认组)
若干次要组
用户可以在不同组身份之间进行切换Linux不支持嵌套组
组成员只能是用户,不能是其他组
组的类别
超级组(Superuser Group)
• 组名:root
• GID:0
• 不像root用户一样具有超级权限
系统组(System Group)
• 由系统或应用程序使用
• GID:1-999、65534
自定义组
• 由管理员创建
• GID:默认从1000开始顺序编号
• 私有组:创建用户时自动创建的同名自定义组
• 标准组:私有组之外的自定义组
组配置文件
组账户配置文件
/etc/group
- 存放除密码之外的组账户信息
- 所有用户均可读取
- 记录格式:man 5 group
组密码配置文件
/etc/gshadow
- 存放与组密码相关的信息
- 除root外,所有用户均无法读取
- 记录格式:man 5 gshadow
验证账号文件的一致性
不建议直接编辑修改系统账户文件,直接编辑账户文件后建议检测账号文件的一致性
pwck
检测/etc/passwd和/etc/shadow的字段格式和值
grpck
检测/etc/group和/etc/gshadow的字段格式和值
useradd 添加用户
- -g 指定新用户的主(私有)组
- -G 指定新用户的附加组
- -d 指定新用户的主目录
- -s 指定新用户使用的Shell,默认为bash
- -e 指定用户的登录失效时间,如08/10/2001
passwd 修改密码
passwd
让用户免密码进行本地登录的两种方法:
- 将/etc/passwd 文件中的密码字段清空
- 将/etc/shadow 文件中的密码字段清空
远程用户必须设置了登录密码才允许登录!
id 查询用户信息
usermod 修改用户账户
userdel 删除用户
groupadd 添加组
gpasswd 设置组密码
groupmod 修改组
groupdel 删除组
groups 查询组信息
用户权限
chmod
更改权限
仅文件所有者和 root 用户有权修改文件权限
1 | |
chown
改变文件的所有者和属组
• 只有root用户才能改变文件的所有者
• 只有root用户或所有者才能改变文件所属的组 (所有者必须是该组成员)
1 | |
进程与作业管理
进程
进程由程序产生,是动态的概念,代表一个运行着的、 要占用系统运行资源的程序。
内核通过进程控制块(Process Control Block, PCB) 来管理每个进程,每个PCB都具有一个唯一的进程标 识符,即PID。
父进程与子进程
一个进程启动另一个进程,就成为父进程,被启动的 进程就是该父进程的子进程
1 | |
ps 查看进程
ps (process status):显示进程列表及其状态
1 | |
搜索进程
1 | |
top 查看动态的进程信息
nohup 后台运行进程
- 通常当用户注销后,所有属于该用户的进程将全 部被终止(SIGHUP)
- 如果希望程序在退出系统后仍然能够继续运行, 可以使用 nohup 命令启动该进程。
- nohup 命令 [选项] [参数] [输出文件] &
1 | |
lsof 查看进程打开的文件
lsof:list open files
1 | |
shell脚本编程
执行shell脚本
1 | |
与位置参数有关的变量
1 | |
shift
shift [n]:所有位置参数左移n位(默认左移1位)
1 | |
由于一共使用shift将位置参数左移4位,所以最后只剩5 6 7 8 9参数了
变量
1 | |
shell中的变量默认是字符串
unset 删除变量
1 | |
此时x变量是没有定义的、没有值
decalre 声明变量
1 | |
特殊变量
1 | |
命令替换
$(),在这里面可以执行命令,或者使用反引号**`**也可以进行命令替换
1 | |
变量替换
在双引号""中,可以使用${}的形式来在字符串中替换变量的值(使用{}括起来可以精确表示变量的开始范围)
1 | |
条件变量替换
以下变量替换中如果包含冒号”:”,则检查变量是否 存在或其值是否为null,如果不包含冒号,则仅检查 变量是否存在。
1 | |
截断变量替换
以下变量替换并未改变变量本身的值
1 | |
获取变量长度
在变量前面加个#可以计算变量长度 `$